

A new Apple patent (number 7975134) at the US Patent & Trademark Office involves a macroscalar processor architecture.
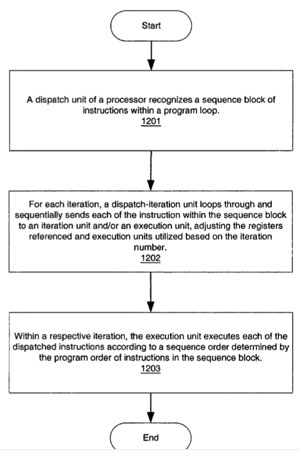
In one embodiment, an exemplary processor includes one or more execution units to execute instructions and one or more iteration units coupled to the execution units. The one or more iteration units receive one or more primary instructions of a program loop that comprise a machine executable program. For each of the primary instructions received, at least one of the iteration units generates multiple secondary instructions that correspond to multiple loop iterations of the task of the respective primary instruction when executed by the one or more execution units. Other methods and apparatuses are also described. Jeffry E. Gonion is the inventor.
Here’s Apple’s background of the invention: “As clock frequencies continue to rise in response to increased demands for performance, power has also increased, while deeper pipelines have exhibited a diminishing effect on the number of instructions per cycle (IPC) achieved in real-world situations, which further contributes to the power dissipation problem through inefficiency. A variety of mechanisms have emerged over the years that attempt to salvage instruction-level parallelism (ILP), such as SMT (simultaneous multi-threading) and VLIW (very long instruction word) and out-of-order execution, some with more success than others.
“The classic compile-time optimization that permits more effective utilization of longer pipelines is loop unrolling. Unfortunately, most processors lack the requisite number of program registers to permit enough unrolling to fully saturate deeper pipelines. Increasing the number of registers without compromising software compatibility is problematic as well. Furthermore, many types of loops simply cannot be unrolled, such as those that implement data-dependent control-flow, which is the same class of loop hit hardest by deeper pipelines.
“Autovectorization is another compiler optimization that is beginning to break into the mainstream. For loops that can be autovectorized, the promise of performance is even greater than for loop unrolling. However, loops that can be autovectorized are only a small subset of loops that can be unrolled, which is a small subset of all loops in general. While regularly structured numerical algorithms sometimes may benefit from auto-vectorization, none of this really helps data-driven algorithms.
“While consumers purchase newer and faster processors with deeper pipelines, the vast majority of software available is still targeted for processors with shorter pipelines. As a result, of this, the consumer may not realize the full processing potential of a new processor for one to two years after its release, and only after making additional investments to obtain updated software. Since the limited number of program registers restricts loop unrolling, it is questionable how efficiently deeper pipelines will actually be utilized.”