Apple has filed for a patent (number 11475608) for “face image generation with pose and impression control.” It involves even more realistic Animoji and Memoji
Background of the patent filing
Animojis allow a user to choose an avatar (e.g., a puppet) to represent themselves. The Animoji can move and talk as if it were a video of the user. Animojis enable users to create personalized versions of emojis in a fun and creative way, and Memoji is the name used for Apple’s personalized “Animoji” characters that can be created and customized right within Messages by choosing from a set of inclusive and diverse characteristics to form a unique personality.
In the patent filing, Apple notes that machine learning techniques have been applied to generate synthetic still images and video sequences. The tech giant wants to make them even more realistic.
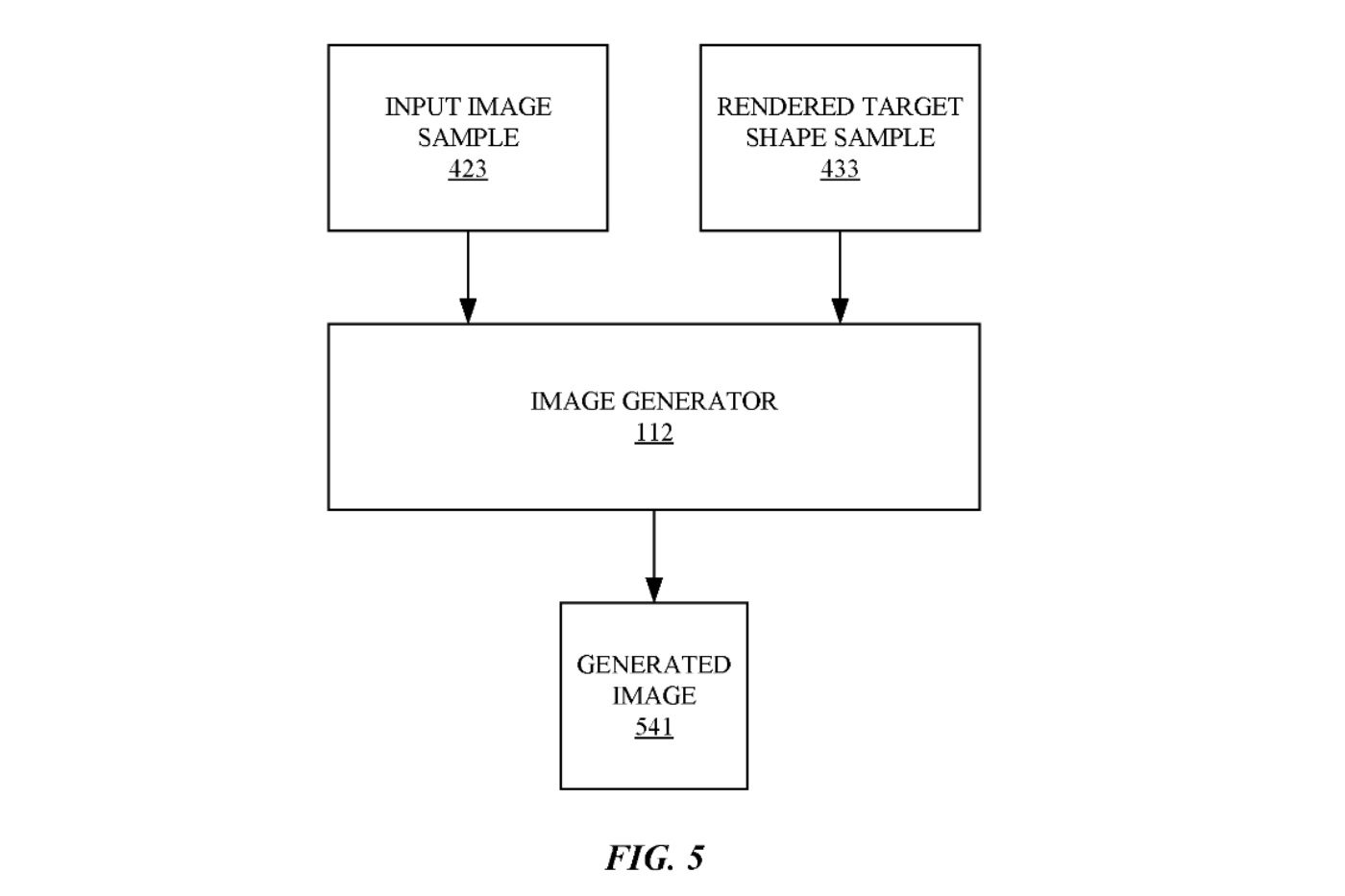
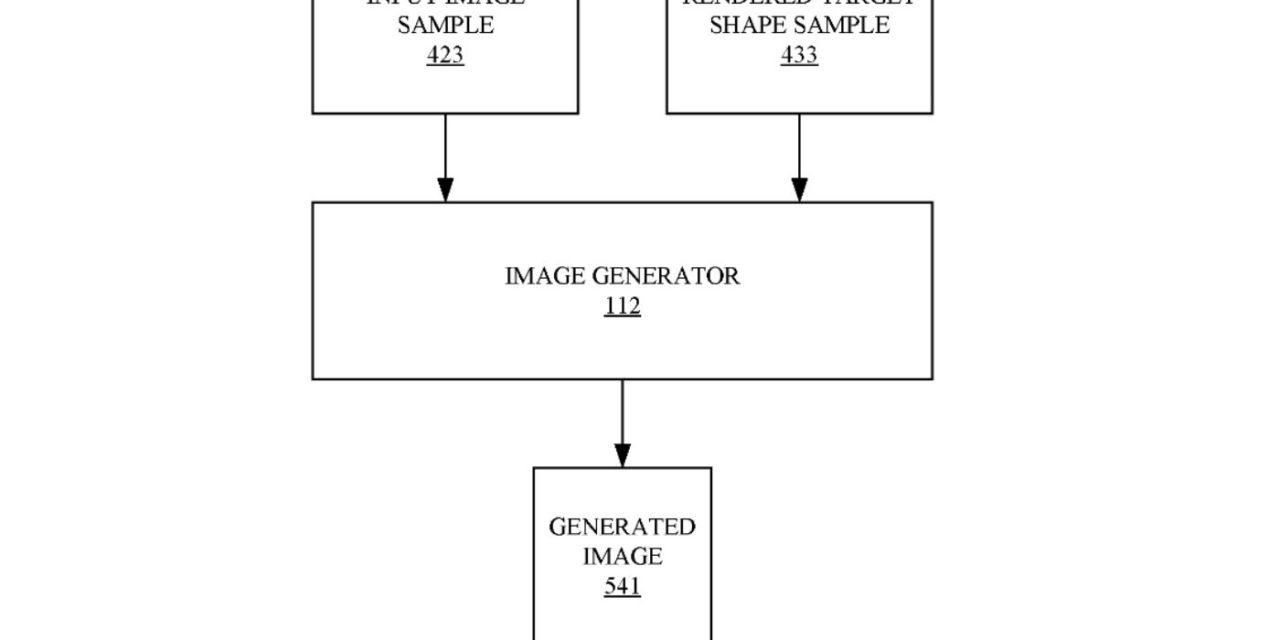
The method described in the patent filing include obtaining an input image that depicts a face of a subject, wherein the face of the subject has an initial facial expression and an initial pose. The method then determines a reference shape description based on the input image and determines a target shape description based on the reference shape description, a facial expression difference, and a pose difference.
Then a target shape image is generated using the target shape description, and generating an output image based on the input image and the rendered target shape using an image generator. The output image is a simulated image of the subject of the input image that has a final expression that is based on the initial facial expression and the facial expression difference, and a final pose that is based on the initial pose and the pose difference.
Summary of the patent filing
Here’s Apple’s abstract of the patent filing: “One aspect of the disclosure is a non-transitory computer-readable storage medium including program instructions. Operations performed by execution of the program instructions include obtaining an input image that depicts a face of a subject, having an initial facial expression and an initial pose, determining a reference shape description based on the input image, determining a target shape description based on the reference shape description, a facial expression difference, and a pose difference, generating a rendered target shape image using the target shape description, and generating an output image based on the input image and the rendered target shape using an image generator, wherein the output image is a simulated image of the subject of the input image that has a final expression that is based on the initial facial expression and the facial expression difference, and a final pose that is based on the initial pose and the pose difference.”
Article provided with permission from AppleWorld.Today